Benchmarking the Speed of Cumulative Functions in TidyDensity
code
tidydensity
benchmark
Author
Steven P. Sanderson II, MPH
Published
January 11, 2024
Introduction
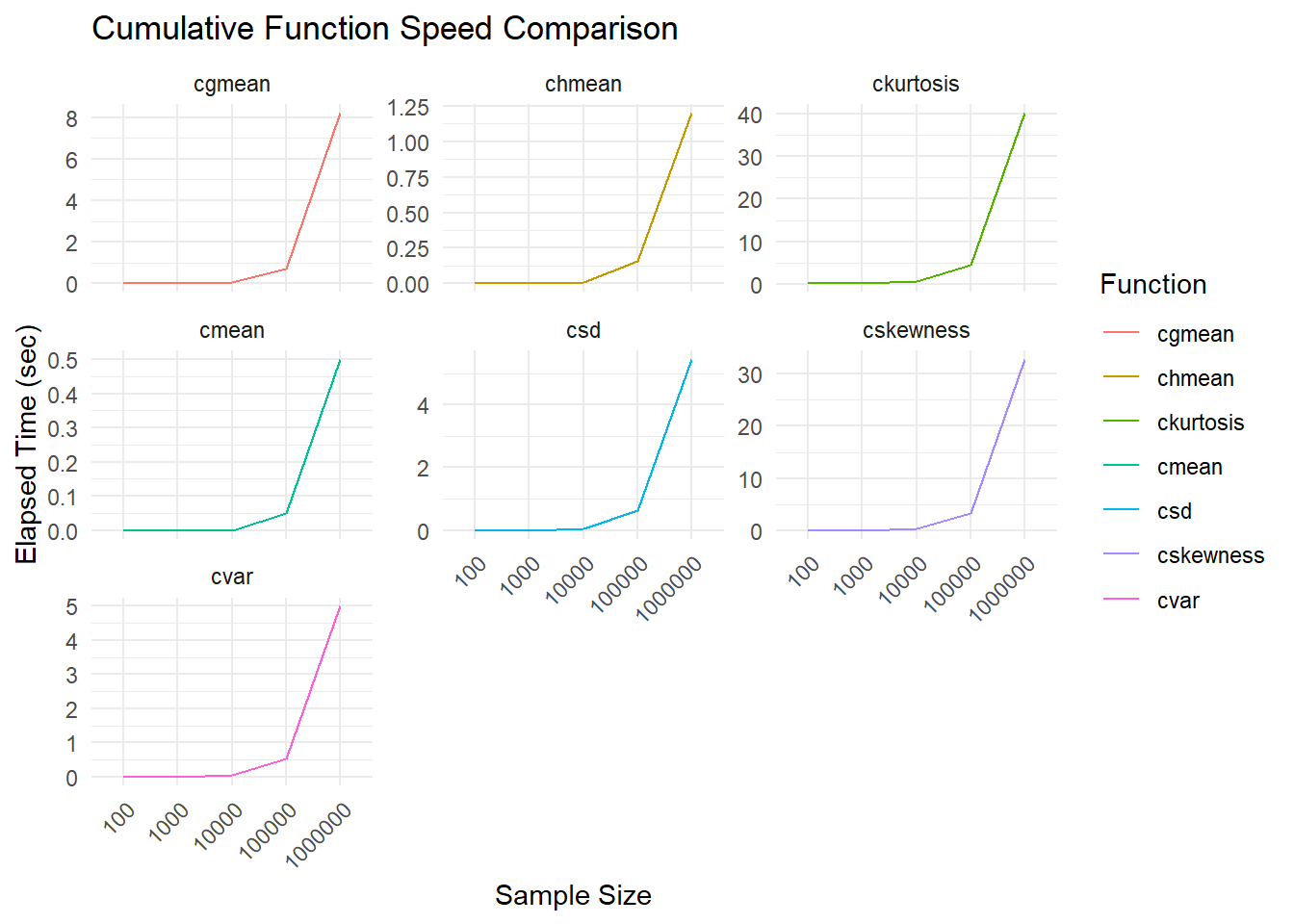
Statistical analysis often involves calculating various measures on large datasets. Speed and efficiency are crucial, especially when dealing with real-time analytics or massive data volumes. The TidyDensity package in R provides a set of fast cumulative functions for common statistical measures like mean, standard deviation, skewness, and kurtosis. But just how fast are these cumulative functions compared to doing the computations directly? In this post, I benchmark the cumulative functions against the base R implementations using the rbenchmark package.
Setting the bench
To assess the performance of TidyDensity’s cumulative functions, we’ll employ the rbenchmark package for benchmarking and the ggplot2 package for visualization. I’ll benchmark the following cumulative functions on random samples of increasing size:
The results show that the TidyDensity cumulative functions scale extremely well as the sample size increases. The elapsed time remains very low even at 1 million observations. The base R implementations like var() and sd() perform significantly worse when used inside of an sapply at large sample sizes. What was not tested however is cmedian() and this is because the performance is very slow once we reach 1e4 compared to the other functions as such that it would take too long to run the benchmark if it ran at all.
So if you need fast statistical functions that can scale to big datasets, the TidyDensity cumulative functions are a great option! They provide massive speedups over base R while returning the same final result.
Let me know in the comments if you have any other benchmark ideas for comparing R packages! I’m always looking for interesting performance comparisons to test out.