ts_median_excess_plt(
.data,
.date_col,
.value_col,
.x_axis,
.ggplot_group_var,
.years_back
)Introduction
As we collect data over time, it’s important to look for patterns and trends that can help us understand what’s happening. One common way to do this is to look at the median of the data. The median is the middle value of a set of numbers, and it can be a useful tool for detecting whether there is an excess of events, either positive or negative, occurring over time.
Benefits of Looking at Median:
Shows the central tendency: The median gives us a good idea of the central tendency of the data. This can help us understand what’s typical and what’s not.
Resistant to outliers: Unlike the mean, the median is not affected by outliers. This means that if there are a few extreme values in the data, the median will not be skewed by them.
Easy to understand: The median is easy to understand, even for people who are not familiar with statistics.
Using the R Library {healthyR} provides a convenient way to perform median analysis. The function ts_median_excess_plt() can be used to plot the median of an event over time and detect any excess events that may be occurring. This function is designed to be user-friendly, so even if you’re not an expert in statistics, you can still use it to gain valuable insights into your data.
In conclusion, looking at the median of an event over time can be a useful tool for detecting excess events, either positive or negative. The R library {healthyR} provides a convenient way to perform this analysis with the function ts_median_excess_plt(). Give it a try and see what insights you can uncover in your own data!
Function
Here is the full function call.
Here are its arguments.
.data- The data that is being analyzed, data must be a tibble/data.frame..date_col- The column of the tibble that holds the date..value_col- The column that holds the value of interest..x_axis- What is the be the x-axis, day, week, etc..ggplot_group_var- The variable to group the ggplot on..years_back- How many yeas back do you want to go in order to compute the median value.
Example
First make sure you have the package installed.
install.packages("healthyR")Now for an example. The data is required to be in a certain format, this function is dated, meaning it was one of the first ones I wrote so I will be taking time to improve it in the future. We are using data from my {healthyR.data]} package.
library(healthyR.data)
library(lubridate)
library(healthyR)
library(dplyr)
library(timetk)
library(ggplot2)
df <- healthyR_data %>%
filter_by_time(
.date_var = visit_start_date_time,
.start_date = "2012",
.end_date = "2019"
) %>%
filter(ip_op_flag == "I") %>%
select(visit_id, visit_start_date_time) %>%
mutate(
visit_start_date_time = as.Date(visit_start_date_time, "%Y%M%D"),
record = 1
) %>%
summarise_by_time(
.date_var = visit_start_date_time,
visits = sum(record)
) %>%
ts_signature_tbl(
.date_col = visit_start_date_time
)Ok now that we have our data, let’s take a look at it using glimpse()
glimpse(df)Rows: 2,922
Columns: 30
$ visit_start_date_time <date> 2012-01-01, 2012-01-02, 2012-01-03, 2012-01-04,…
$ visits <dbl> 34, 52, 53, 44, 46, 55, 42, 29, 50, 55, 50, 43, …
$ index.num <dbl> 1325376000, 1325462400, 1325548800, 1325635200, …
$ diff <dbl> NA, 86400, 86400, 86400, 86400, 86400, 86400, 86…
$ year <int> 2012, 2012, 2012, 2012, 2012, 2012, 2012, 2012, …
$ year.iso <int> 2011, 2012, 2012, 2012, 2012, 2012, 2012, 2012, …
$ half <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ quarter <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ month <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ month.xts <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ month.lbl <ord> January, January, January, January, January, Jan…
$ day <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 1…
$ hour <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ minute <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ second <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ hour12 <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ am.pm <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ wday <int> 1, 2, 3, 4, 5, 6, 7, 1, 2, 3, 4, 5, 6, 7, 1, 2, …
$ wday.xts <int> 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, …
$ wday.lbl <ord> Sunday, Monday, Tuesday, Wednesday, Thursday, Fr…
$ mday <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 1…
$ qday <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 1…
$ yday <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 1…
$ mweek <int> 5, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 3, …
$ week <int> 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 3, 3, …
$ week.iso <int> 52, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 3,…
$ week2 <int> 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, …
$ week3 <int> 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 0, 0, …
$ week4 <int> 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 3, 3, …
$ mday7 <int> 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, …Now to visualize it.
df %>%
ts_median_excess_plt(
.date_col = visit_start_date_time,
.value_col = visits,
.x_axis = month.lbl,
.ggplot_group_var = year,
.years_back = 3
) +
labs(
y = "Excess Visits",
title = "Excess Visits by Month YoY"
) +
theme(axis.text.x=element_text(angle = -90, hjust = 0))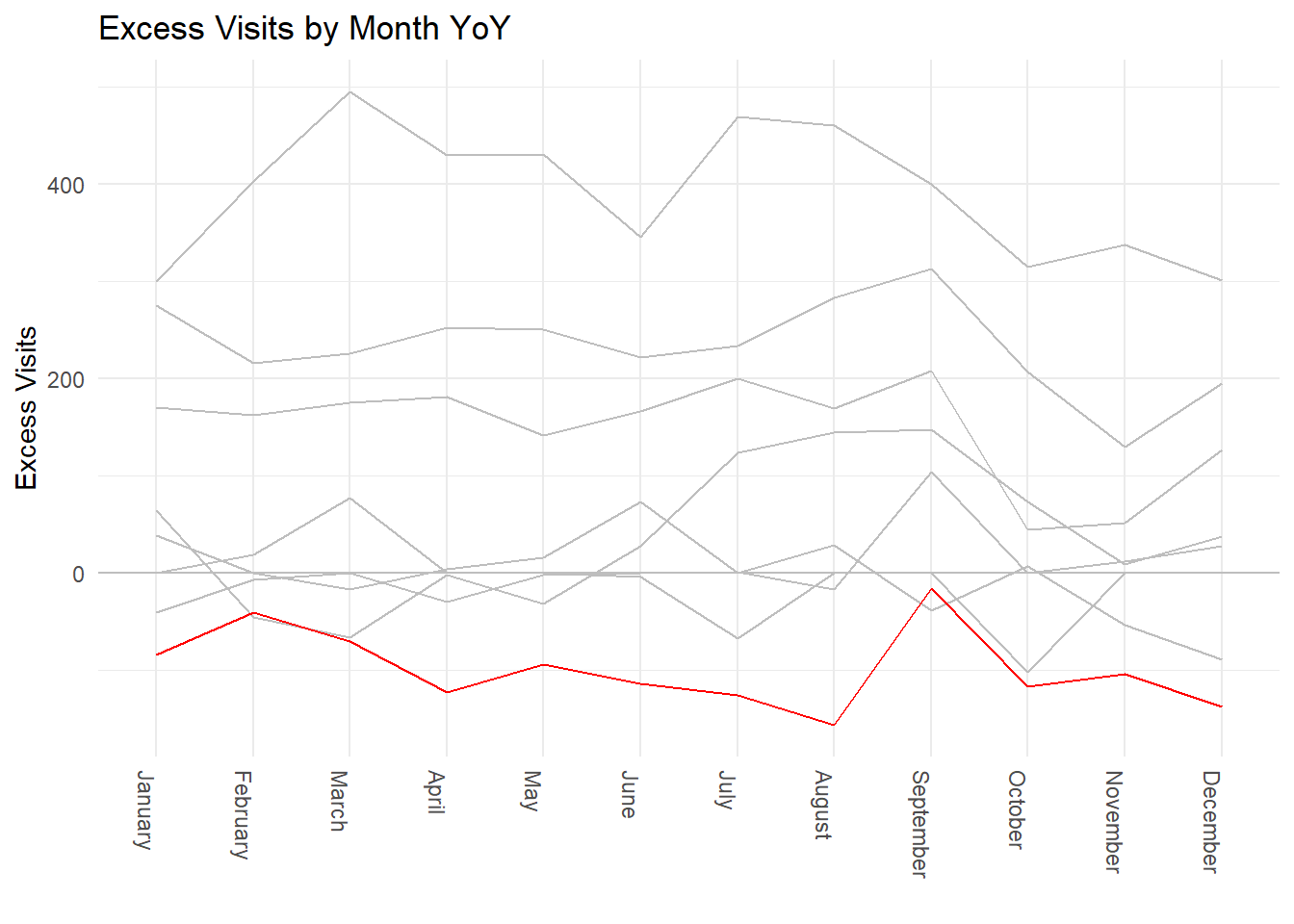
So from here what we can see is that looking back in time over the visits data that the current year (the max year in the data) shows that it is significantly under previous years median values by month.
Voila!